|
La indexación es la última etapa del proceso de captura y durante ella, se registrarán los documentos (SE Documento) generados a partir del lote de captura. Esta sección está dividida en dos subsecciones:
Definiciones de salida
En esta sección, es posible establecer las definiciones de salida de los archivos del lote de captura. Para eso, los siguientes campos están disponibles:
Categoría
|
Seleccione la categoría en la que se guardarán los documentos por lote. Consulte la documentación específica del componente SE Documento para obtener más información sobre el registro y configuración de una categoría de documentos.
|
Opción
|
Marcada
|
Desmarcado
|
Selección dinámica de categoría
|
Será permitido:
▪Seleccionar una categoría diferente para cada documento del lote (si hay más de un documento en el lote); ▪Definir la categoría por medio de un índice del perfil de reconocimiento, en la ejecución de la etapa de indexación. |
Los documentos del lote se guardarán en la categoría definida anteriormente, y no será posible modificarla.
|
Formato del archivo
|
PDF (solo imagen)
|
Seleccione esta opción para que los archivos electrónicos se guarden en el documento en formato PDF bitmap, es decir, si el archivo electrónico contiene texto, no será posible buscar palabras en él.
|
PDF que permite búsqueda
|
Seleccione esta opción para que los archivos electrónicos sean guardados en el documento en formato PDF y después de pasar por OCR, será posible realizar búsquedas de palabras en su contenido.
|
PDF/A
|
Seleccione esta opción para que los archivos electrónicos sean guardados en el documento con el estándar PDF/A, también conocido como ISO19005-1, que consiste en un archivo estándar, o sea, preserva el archivo electrónico para que él pueda ser visualizado, con la misma apariencia, a largo plazo. Esta opción no permite realizar búsqueda por palabras en su contenido.
|
TIFF multipage
|
Seleccione esta opción para que los archivos electrónicos sean guardados en el documento en formato TIFF multipágina. TIFF es un formato gráfico de alta resolución basado en tags (etiquetas) utilizado para intercambiar elementos gráficos digitales. A través del recurso de etiquetas, un único archivo .tiff compuesto de varias páginas puede almacenar diversas imágenes, junto con información relacionada, como el tipo de compresión y orientación.
|
Imágenes
|
Seleccione esta opción para que los archivos electrónicos sean guardados en el documento en el formato de imagen. En el campo de al lado, seleccione la extensión deseada: TIFF, JPEG o GIF.
|
Compresión JPEG
|
Si el formato definido anteriormente es "Imágenes" y "JPEG", seleccione el nivel de compresión que será aplicado al archivo electrónico:
|
Regular
|
Al configurar el nivel de compresión, debe tener en cuenta que: un nivel de compresión alto produce tamaños de archivo más pequeños e imágenes de baja calidad, mientras que un nivel de compresión bajo produce archivos más grandes y una calidad de imagen alta.
Una imagen JPEG de baja calidad no es necesariamente una mala imagen.
|
Bueno
|
Mejor
|
Personalizado
|
Informe el nivel de compresión deseado.
|
OCR
|
Marcada
|
Desmarcado
|
Binarizar la imagen para hacer OCR1
|
El sistema convertirá la imagen del lote a blanco y negro antes de cualquier operación de OCR.
Por ejemplo, si la imagen utilizada por el lote es de color o escala de grises, cuando se ejecuta un paso de captura donde es necesario realizar OCR, el sistema binarizará la imagen, hará el OCR y, a continuación, descartará la imagen en blanco y negro, manteniendo la imagen en color.
|
El sistema no convertirá una imagen en color del lote a blanco y negro antes de la realización del OCR.
|
1 - Esta opción solo estará disponible para edición después de guardar el registro por primera vez, si la etapa "Reconocimiento" está parametrizada y si el formato del archivo es "PDF que permite búsqueda".
Después de guardar el registro de la configuración de captura por primera vez, si la categoría seleccionada tiene atributos asociados, estos se pueden utilizar en la sección "Procesamiento".
|
Proceso
En esta sección, son configurados los datos que compondrán el documento que será creado en la categoría seleccionada en la sección "Definiciones de salida". Para eso, accione el botón  de la barra de herramientas lateral. En la pantalla que será presentada, configure los siguientes campos: de la barra de herramientas lateral. En la pantalla que será presentada, configure los siguientes campos:
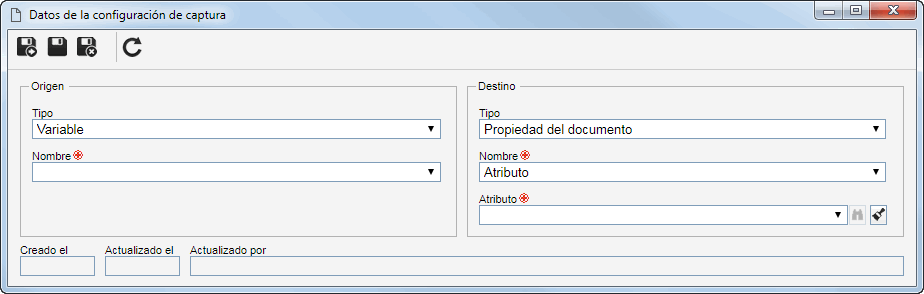
Origen
|
Defina dónde será obtenido el registro que será utilizado para componer una propiedad del documento creado a partir del lote de captura. Para eso, en el campo Tipo, seleccione la opción deseada:
Tipo
|
Variable
|
Los datos de origen serán una variable previamente registrada en el sistema.
En el campo Nombre seleccione la variable deseada.
|
Base de datos1
|
El dato de origen será uno de los metadatos del modelo utilizado en el servicio asociado a la configuración de captura.
En el campo Nombre, seleccione el metadato deseado.
|
Fuente de datos Webservice2
|
El dato de origen será una variable de retorno del Web Service asociado a la configuración de captura.
En el campo Nombre, seleccione el metadato deseado.
|
Perfil de reconocimiento3
|
El dato de origen será uno de los índices configurados en el perfil de reconocimiento asociado a la configuración de captura. Para eso, llene los siguientes campos que serán presentados:
▪Perfil de reconocimiento: Si el tipo de lote es "Múltiples documentos" y el tipo de documento es "Imagen" y se asocia más de un perfil de reconocimiento a la configuración de captura, puede seleccionar el perfil de reconocimiento que desea utilizar como datos de origen. En caso contrario, este campo se llenará por el sistema con el perfil de reconocimiento asociado a la configuración de captura. ▪Nombre del índice: Seleccione el índice del perfil de reconocimiento seleccionado anteriormente, que desea utilizar como datos de origen. |
Cant. de páginas
|
El dato de origen será el número de páginas que el documento contiene.
|
Nombre del archivo
|
El dato de origen será el nombre del archivo importado en el lote. Si el documento tiene más de un archivo, se utilizará el nombre del primer archivo del documento.
|
Valor fijo
|
El dato de origen será un valor predefinido. En este caso, informe en el respectivo campo, el valor deseado.
|
1 -Solo estará disponible si la configuración de captura tiene relaciones configuradas en la sección "Relación".
2 - Esta opción solo estará disponible si en la sección Relación, se configura que esta será por "Fuente de datos Web Service".
3 - Esta opción solo estará disponible si la configuración de captura tiene un perfil de reconocimiento asociado en la sección "Reconocimiento".
|
Destino
|
Configure donde será utilizado el valor obtenido por medio del origen, en el documento creado a partir del lote de captura. Para eso, en el campo Tipo, seleccione la opción deseada:
El valor será una propiedad del documento que será creado. En el campo Nombre seleccione la propiedad deseada:
Propiedad del documento
|
Identificador
|
El valor será utilizado en el campo "Identificador" del documento creado a partir del lote.
|
Título
|
El valor será utilizado en el campo "Título" del documento creado a partir del lote.
|
Resumen
|
El valor será el campo "Resumen" del documento creado a partir del lote.
|
Atributo
|
El valor será aplicado al atributo del documento creado a partir del lote. En el campo Atributo, que será habilitado:
▪Serán presentados, si existen, los atributos asociados a la categoría que fue seleccionada en la sección "Definición de salida". ▪Si la opción "Selección dinámica de categoría" ha sido marcada, estarán disponibles para selección todos los atributos registrados en el componente SE Documento. |
Contenedor de archivo complejo
|
El valor será utilizado en el campo "Contenedor de archivo complejo" de la categoría del documento creado a partir del lote.
|
Categoría
|
El valor será utilizado en el campo "Categoría" del documento creado a partir del lote.
|
Nueva variable
|
Nombre
|
Informe el nombre de la variable que será creada conteniendo como valor, el dato de origen.
|
Variable existente
|
Nombre
|
Seleccione la variable deseada. Esta será el valor obtenido.
|
Concatenar valor de la variable
|
▪Marcada: El valor obtenido del origen será concatenado después (al final) del valor existente. ▪Desmarcada: El dato obtenido del origen sustituirá el valor de la variable seleccionada. |
Expresión regular
|
Nombre
|
Informe un nombre para la expresión regular. Este nombre quedará disponible como una nueva variable que luego puede ser la fuente de origen de una propiedad del documento.
|
Estándar de correspondencia
|
Informe la expresión regular a partir de la cual se obtendrá el valor del origen.
|
El valor será el dato obtenido de un campo del formulario asociado como modelo en la categoría (SE Documento) que fue seleccionada en la sección "Definición de salida". Para que este recurso funcione correctamente, es necesario que SE Formulario forme parte de las soluciones adquiridas por su organización. Utilice los siguientes campos que serán presentados:
Campos del formulario
|
Entidad
|
Seleccione el formulario modelo de la categoría a la cual pertenecerá el documento.
|
Campo de la entidad
|
Seleccione el campo del formulario del cual será obtenido el valor deseado.
|
El campo de destino será un extracto tomado del origen definido anteriormente. Para eso, utilice los siguientes campos que serán presentados:
Función extraer texto
|
Nombre
|
Informe un nombre para la función. Este nombre quedará disponible como una nueva variable que luego puede ser la fuente de origen de una propiedad del documento.
|
Carácter inicial
|
Informe el número que corresponde a la posición del carácter a partir del cual se iniciará la extracción del texto.
Por ejemplo, cuando se informa el número 1, la extracción se iniciará a partir del 1er carácter presentado en el texto.
|
Cantidad de caracteres
|
Informe cuántos caracteres, a partir del carácter inicial, serán extraídos para formar el valor deseado.
Por ejemplo, si el carácter inicial es 1, y es informada la cantidad de 5 caracteres, del 1º al 5º carácter formarán el valor deseado.
|
El campo de destino será un pedazo de un texto obtenido del origen definido anteriormente. Para eso, utilice los siguientes campos que serán presentados:
Función dividir texto
|
Nombre
|
Informe un nombre para la función. Este nombre quedará disponible como una nueva variable que luego puede ser la fuente de origen de una propiedad del documento.
|
Delimitador
|
Informe el carácter que será utilizado como divisor.
Por ejemplo, cuando se informa el carácter ";" y el origen es compuesto por el valor "Nombre;fecha;estado civil", el sistema dividirá el texto en 3 valores: "Nombre", "fecha" y "estado civil".
|
Posición
|
Informe el número correspondiente al segmento o tramo que desea usar como valor.
Por ejemplo, al informar el valor 2, en el ejemplo citado anteriormente, será utilizado solo el valor "fecha".
|
|
Después de realizar las configuraciones deseadas, guarde el registro. Utilice los demás botones de la barra de herramientas lateral para editar y excluir el dato seleccionado en la lista de registros.
|