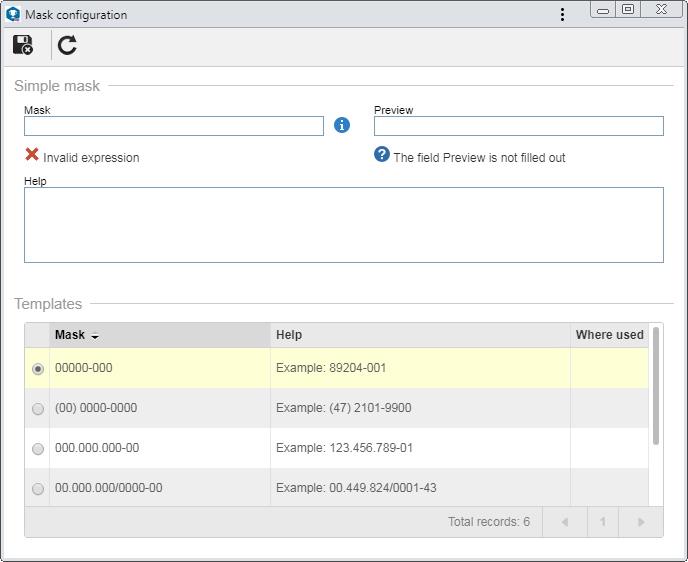
After selecting the "Regular expression" mask in the Type field, click on the  button located next to the Mask field. The regular expression configuration screen that will be opened is divided into the following sections: button located next to the Mask field. The regular expression configuration screen that will be opened is divided into the following sections:
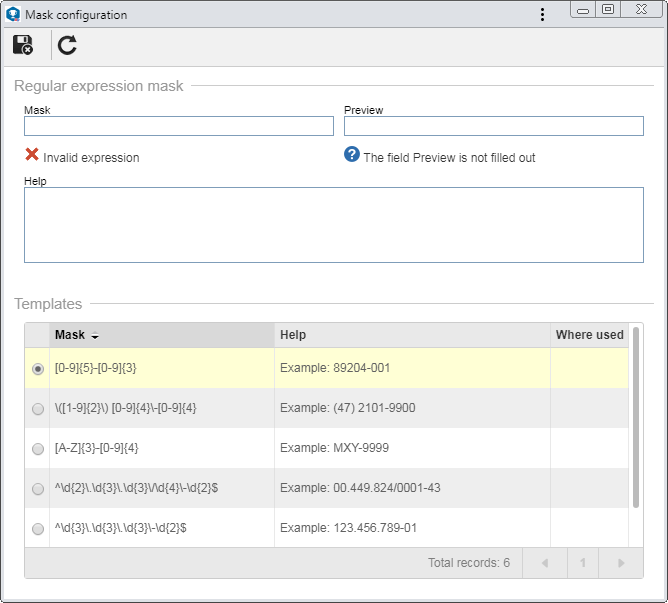
Regular expression mask
|
Mask
|
Enter the regular expression that will make up the attribute mask. Right below the field, it is possible to view whether the mask informed is valid.
|
Preview
|
Enter a value to validate whether the entered expression meets your needs. When filling out this field, right below it, it will be possible to view when the entered value is valid.
|
Help
|
Record important information that may help with filling out the attribute value. For example: Enter only numbers, with no dots or spacing. The text informed in this field will be displayed next to the field that must be filled with the value configured in the mask for the attribute.
|
Templates
|
In this section, some expressions that may be applied to the attribute that is being created are displayed. The expressions shown in this section are preconfigured, but the expressions used in some other indeterminate attribute may be displayed. To apply a regular expression from this section, just double click on it. At this moment, the Mask and Help fields will be filled by the system with the selected regular expression information.
|
After filling in the necessary fields, save the record.
Building a regular expression
A regular expression is a notation to describe a pattern of characters. It is used to validate data input or to search and extract information on texts. For example, to verify if an entered piece of data is a number from 0.00 to 9.99, it is possible to use the regular expression ^\d,\d\d$ because the \d symbol is a wildcard character that matches one digit. The special characters ^ and $ indicate, respectively, how the string must start and end; without them, the numbers 10.00 or 100.123 would be valid, because they contain digits that match the regular expression.
A metacharacter is a character or a sequence of characters with a special meaning in the regular expressions. Metacharacters can be categorized according to their use.
Specifiers
They specify the character set to be matched in a position.
Metacharacter
|
Description
|
.
|
Wildcard: Matches any character, except the \n line break.
|
[...]
|
Set: Matches any character added in the set. For example:
▪[a-z] will accept strings with lowercase characters between 'a' and 'z', while [A-Z] accepts uppercase characters between 'A' and 'Z'. ▪[abcABC] will accept strings that contain only the 'a', 'b', 'c', 'A', 'B' and/or 'C' characters. ▪[123] will accept strings that contain only the '1', '2' and/or '3' characters; ▪[0-9] will accept strings with characters between '0' and '9'. |
[^...]
|
Denied set: Matches any character that is not included in the set.
|
\d
|
Digit: the same as [0-9].
|
\D
|
Non-digit: the same as [^0-9].
|
\s
|
Whitespace character: space, line break, tabs etc.; the same as [\t\n\r\f\v].
|
\S
|
Non-whitespace character: the same as [^ \t\n\r\f\v].
|
\w
|
Alphanumeric: the same as [a-zA-Z0-9_] (but may include Unicode characters)
|
\W
|
Non-alphanumeric: the complement of \w.
|
\
|
Escape: annuls the special meaning of a metacharacter; for example, \. represents only a point, and not the wildcard character.
|
Quantifiers
They define the allowed number of repetitions for the regular expression right before it.
Metacharacter
|
Description
|
{n}
|
Allow exactly n occurrences. For example:
▪[abc]{3}: Accepts strings containing 3 characters, such as 'a', 'b' or 'c', such as: aaa, abc, acb, bba, etc. ▪[0-9]{5}: Accepts 5-character strings between '0' and '9', such as: 11111, 12345, 15973, etc. |
{n,m}
|
Allows at least n occurrences and at most m. For example:
▪[abc]{3,5}: Accepts strings containing between 3 and 5 characters, them being 'a', 'b' or 'c', such as: aaaaa, acbca, abc, acba, etc. ▪[0-9]{5,6}: Accepts strings containing 5 or 6 characters between '0' and '9', such as: 12345, 123456, 01030, 000000, etc. |
{n,}
|
Allows at least n occurrences. For example:
▪[abc]{2,}: Accepts strings containing at least 2 characters, them being 'a', 'b' or 'c', such as: aa, abc, ccc, abcabc, etc. ▪[0-9]{2,}: Accepts strings containing at least 2 characters between '0' and '9', such as: 12, 123, 987654321, etc. |
?
|
Allows 0 or 1 occurrence; the same as {0,1}.
|
+
|
Allows 1 or more occurrences; the same as {1,}.
|
*
|
Allows 0 or more occurrences.
|
Anchors
They establish reference positions for the matching of the remainder of the regular expression. Notice that these metacharacters do not match characters in the text, but rather with positions before, after, or between characters.
Metacharacter
|
Description
|
^
|
Matches the beginning of a string.
|
$
|
Matches the end of a string; does not capture the \n at the end of the text or line.
|
\A
|
Beginning of the text.
|
\Z
|
End of the text.
|
\b
|
Boundary position: Finds a correspondence at the beginning or at the end of a string; the same as the position between \W and \w or vice versa.
|
\B
|
Non-boundary position.
|
Grouping
It defines groups or alternatives.
Metacharacter
|
Description
|
(...)
|
Defines a group, for the purpose of applying a quantifier, alternative or later extraction or reuse.
|
...|...
|
Alternative; matches the regular expression to the right or to the left.
|
\«n»
|
Retrieves the text matched in the nth group.
|
Examples: To provide a general idea, see some examples with a brief explanation:
\d{5}-\d{3}
|
The pattern of a zip code like 05432-001: 5 digits, a - (hyphen) and 3 more digits. The sequence \d is a metacharacter, a wildcard character that matches a digit (0 to 9). The sequence {5} is a quantifier: it indicates that the previous pattern must be repeated 5 times, so \d{5} is the same as \d\d\d\d\d.
|
[012]\d:[0-5]\d
|
Similar to the hour and minute format, such as 03:10 or 23:59. The sequence between brackets [012] defines a set. In this case, the set specifies that the first character must be 0, 1, or 2. Inside the [], the hyphen indicates a range of characters; that is, [0-5] is a short form for the set [012345]. The set that represents all the digits, [0-9], is the same as \d. Notice that this regular expression also accepts the text 29:00, which is not a valid time.
|
[A-Z]{3}-\d{4}
|
It is the standard for a license plate in Brazil: three letters from A and Z, followed by a - (hyphen), followed by four digits, such as CKD-4592.
|
|