OCR |
|
|
The following are the rules available when the OCR option is selected in the recognition profile:
OptionalWhen you select this rule, the system will recognize the specific area or the full page and extract the captured value. See below an example of its application:
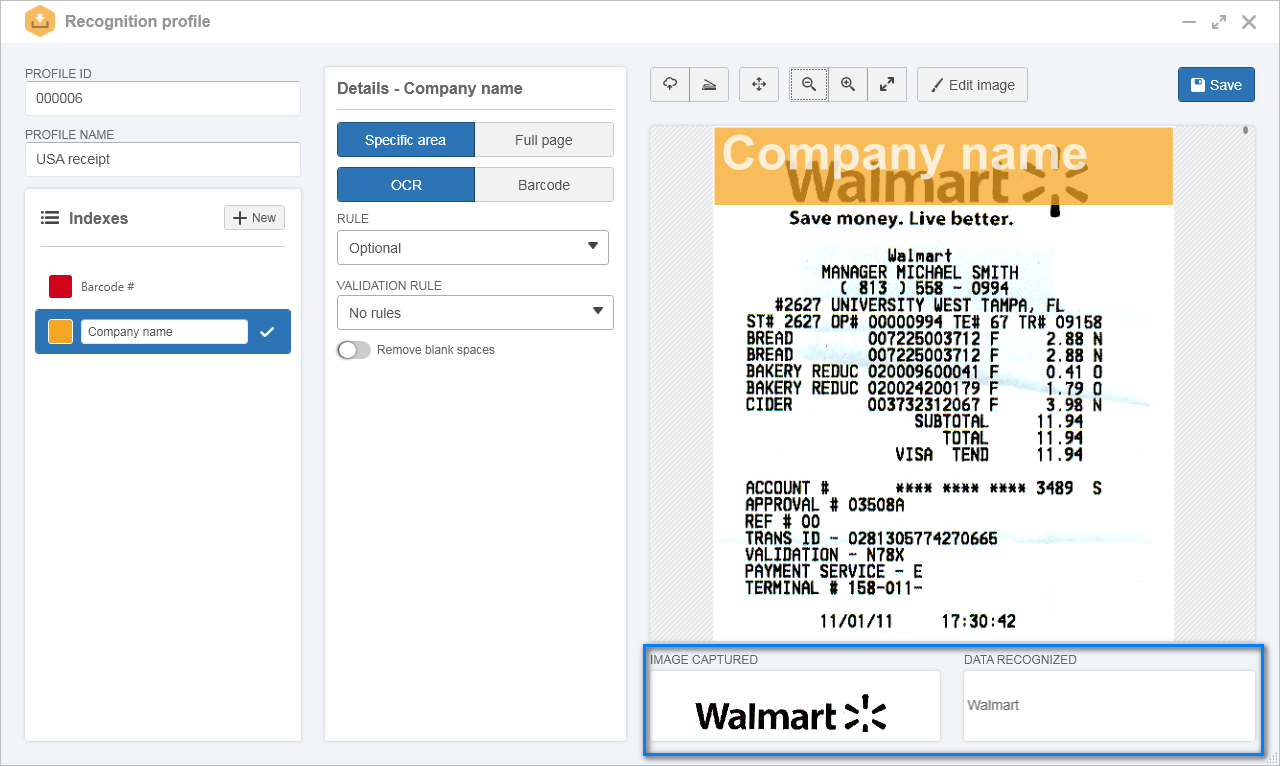
1.In the recognition profile, after setting an ID # and a name, the image of a customer receipt was imported.
2.In the Indexes panel, an index called "Company name" was configured.
3.In the index details, it was defined that the recognition would be done considering a specific area. After that, the OCR option and the Optional rule was selected.
4.In the preview panel, the index was delimited in the place where, commonly, the company name is found, in a customer receipt.
Thus, in the Image captured field, it is possible to see that it was only considered the specific area of the customer receipt. In the Data recognized field, the name of the company that issued the customer receipt is displayed:
SubstringBy selecting this rule, the system performs the recognition in the specific area or the full page and extracts the captured value according to the delimitations and instances configured. See below an example of its application:
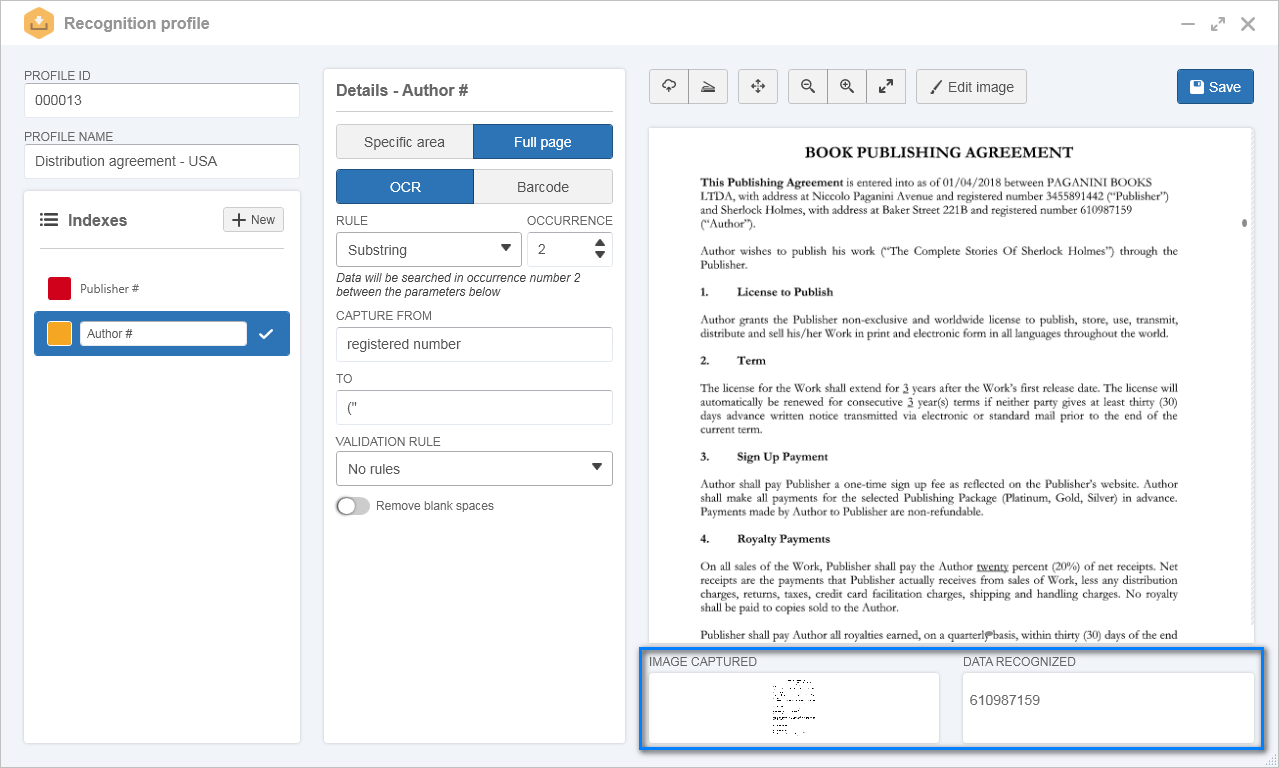
1.In the recognition profile, after setting an ID # and a name for it, the image of a contract was imported.
2.In the Indexes panel, an index called "Phone # - Company" was configured.
3.In the index details, it was set that the recognition would be made considering the full page.
4.After that, the OCR option and the Substring rule was selected, and the following fields were filled out:
Thus, in the Image captured field, it is possible to view that the entire contract page that was considered. In the Data recognized field, the author's ID number is displayed, as specified in the contract:
Line informationBy selecting this rule, the system performs the recognition of a particular row in the specific area or the full page and extracts the captured value according to the delimitations and instances configured. See below an example of its application:
1.In the recognition profile, after setting an ID # and a name, the image of a customer receipt was imported.
2.In the Indexes panel, was configured an index called "Form of payment".
3.In the index details, it was set that the recognition would be made considering the full page.
4.After that, the OCR option and Line information rule was selected, and the following fields were filled out:
Thus, in the Image captured field, it is possible to view that the entire customer receipt page that was considered. In the Data recognized field, the system presents the payment form and the total amount paid as specified in the customer receipt:
OffsetWhen selecting this rule, the system performs recognition within a sensitive area of the specific area or the full page, depending on the delimitations and instances configured. See below an example of its application:
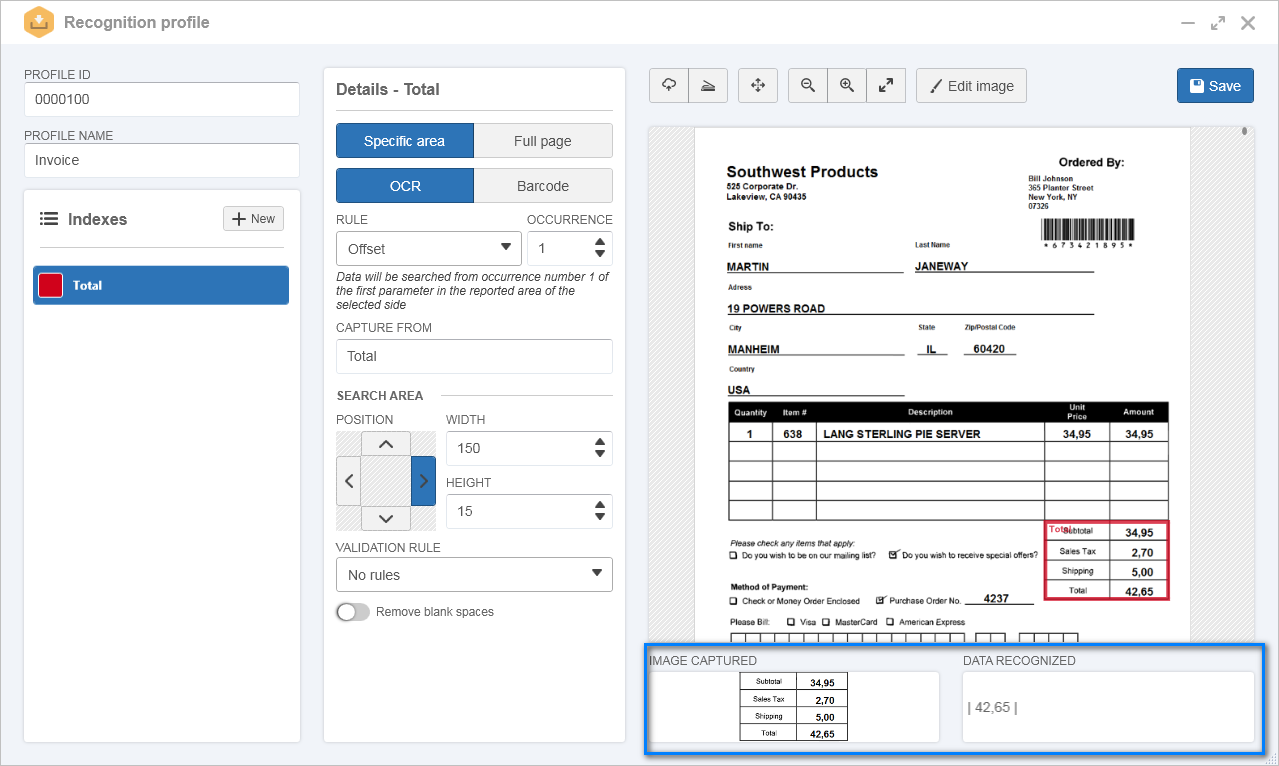
1.In the recognition profile, after setting an ID # and a name for it, the image of a DANFE was imported.
2.In the Indexes panel, an index called "Total" was configured.
3.In the index details, was defined that the recognition would be done considering a specific area.
4.After that, the OCR option and the Offset rule was selected, and the following fields were filled out:
Thus, in the Image captured field, it is possible to view that it was only considered the specific area of the customer receipt. In the Data recognized field, the total value of the receipt is displayed:
MaskWhen selecting this rule, the system performs the recognition in the specific area or the full page and extracts the captured value according to the regular expression configured. See below an example of its application:
1.In the recognition profile, after setting an ID # and a name, the image of a customer receipt was imported.
2.In the Indexes panel, an index called "Total" was configured.
3.In the index details, it was set that the recognition would be made considering the full page.
4.After that, the OCR option and Mask rule was selected, and the following fields were filled out:
Thus, in the Image captured field, it is possible to view that the entire customer receipt page that was considered. In the Data recognized field, the telephone of the company that issued the customer receipt is displayed:
Building a regular expressionA regular expression is a notation for describing a pattern of characters. It serves to validate data inputs or to search and extract information in texts. For example, to verify if an entered piece of data is a number from 0.00 to 9.99, it is possible to use the regular expression ^\d,\d\d$ because the \d symbol is a wildcard character that matches one digit. The ^ and $ special characters indicate, respectively, how the string must start and end; without them, the numbers 10,00 or 100,123 would be valid because they contain digits that match the regular expression. A metacharacter is a character or a sequence of characters with special meaning in the regular expressions. Metacharacters can be categorized according to their use.
Specifiers Specify the set of characters to be married in a position.
QuantifiersThey define the allowed number of repetitions for the regular expression right before it.
AnchorsThey establish reference positions for the matching of the remainder of the regular expression. Notice that these metacharacters do not match characters in the text, but rather with positions before, after, or between characters.
GroupingIt defines groups or alternatives.
Examples: To provide a general idea, see some examples with a brief explanation:
Fixed valueBy selecting this rule, the system allows the user to define a certain value to be used in the classification of the information generated from the recognition profile in question. See below an example of its application:
1.In the recognition profile, after setting an ID # and a name for it, the image of an electricity bill was imported.
2.In the Indexes panel, an index has been configured with the name "Company".
3.In the Rule field of the index details, the Fixed value option was selected. Then, in the Return field, the name of the "Electricity company" was entered.
With that, for example, it is possible to parameterize, in the capture configuration, that all documents generated from the recognition profile (with the fixed value configured) will automatically be recorded in the "Electricity bills" category. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||