OCR |
|
|
Veja a seguir as regras disponíveis quando a opção OCR for selecionada no perfil de reconhecimento:
OpcionalAo selecionar esta regra, o sistema fará o reconhecimento na área específica ou na página inteira e extrairá o valor capturado. Veja a seguir um exemplo de sua aplicação:
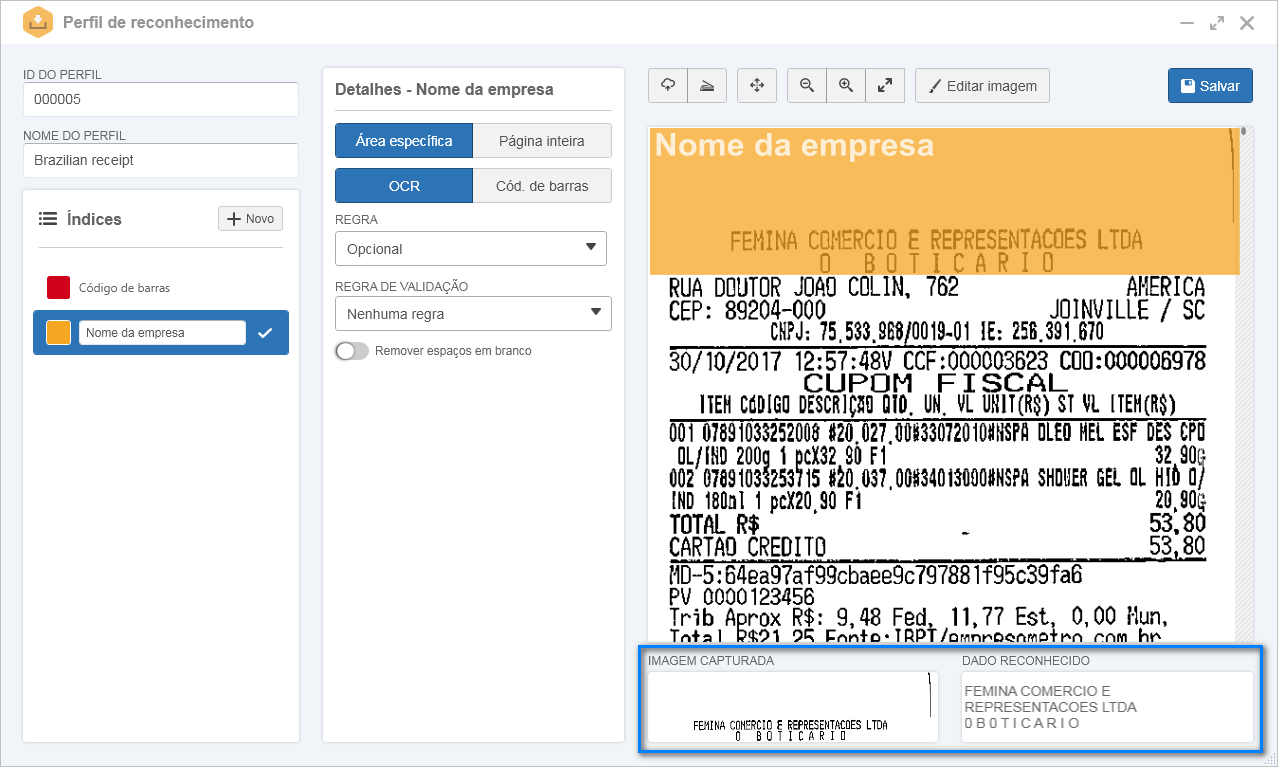
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de um cupom fiscal.
2.No painel Índices, foi configurado um índice chamado "Nome da empresa".
3.Nos detalhes do índice, foi definido que o reconhecimento seria feito considerando uma área específica. Em seguida, foi selecionada a opção OCR e a regra Opcional.
4.No painel de pré-visualização, o índice foi delimitado no local onde, comumente, se encontra a razão social de uma empresa, em um cupom fiscal.
Com isso, no campo Imagem capturada, é possível visualizar que foi considerada somente a área específica do cupom fiscal. No campo Dado reconhecido, é apresentado o nome da empresa emissora do cupom fiscal:
SubstringAo selecionar esta regra, o sistema realiza o reconhecimento na área específica ou na página inteira e extrairá o valor capturado, de acordo com as delimitações e ocorrências configuradas. Veja a seguir um exemplo de sua aplicação:
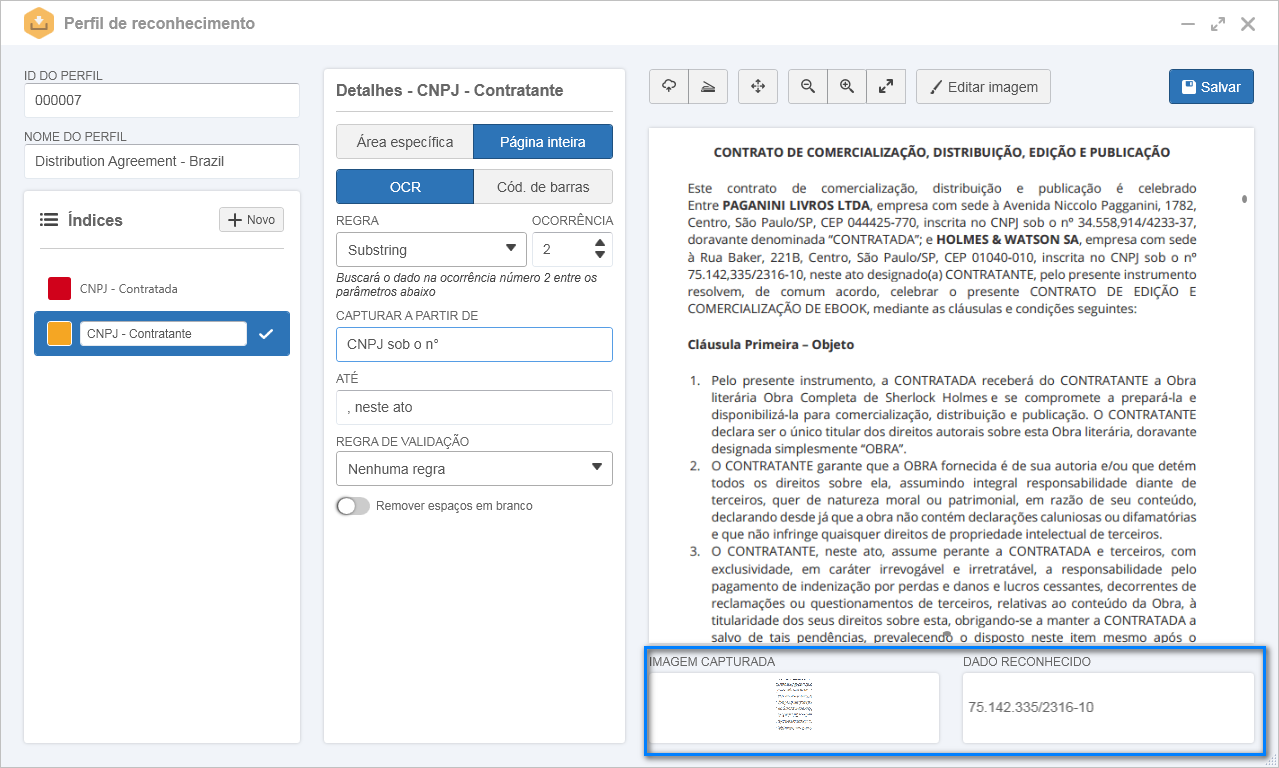
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de um contrato.
2.No painel Índices, foi configurado um índice chamado "CNPJ - Contratante".
3.Nos detalhes do índice, foi definido que o reconhecimento seria feito considerando a página inteira.
4.Em seguida, foi selecionada a opção OCR e a regra Substring e preenchidos os seguintes campos:
Com isso, no campo Imagem capturada, é possível visualizar que foi considerada toda a página do contrato. No campo Dado reconhecido, é apresentado o CNPJ da empresa contratante, conforme especificado no contrato:
Linha de informaçãoAo selecionar esta regra, o sistema realiza o reconhecimento de uma determinada linha na área específica ou na página inteira e extrairá o valor capturado, de acordo com as delimitações e ocorrências configuradas. Veja a seguir um exemplo de sua aplicação:
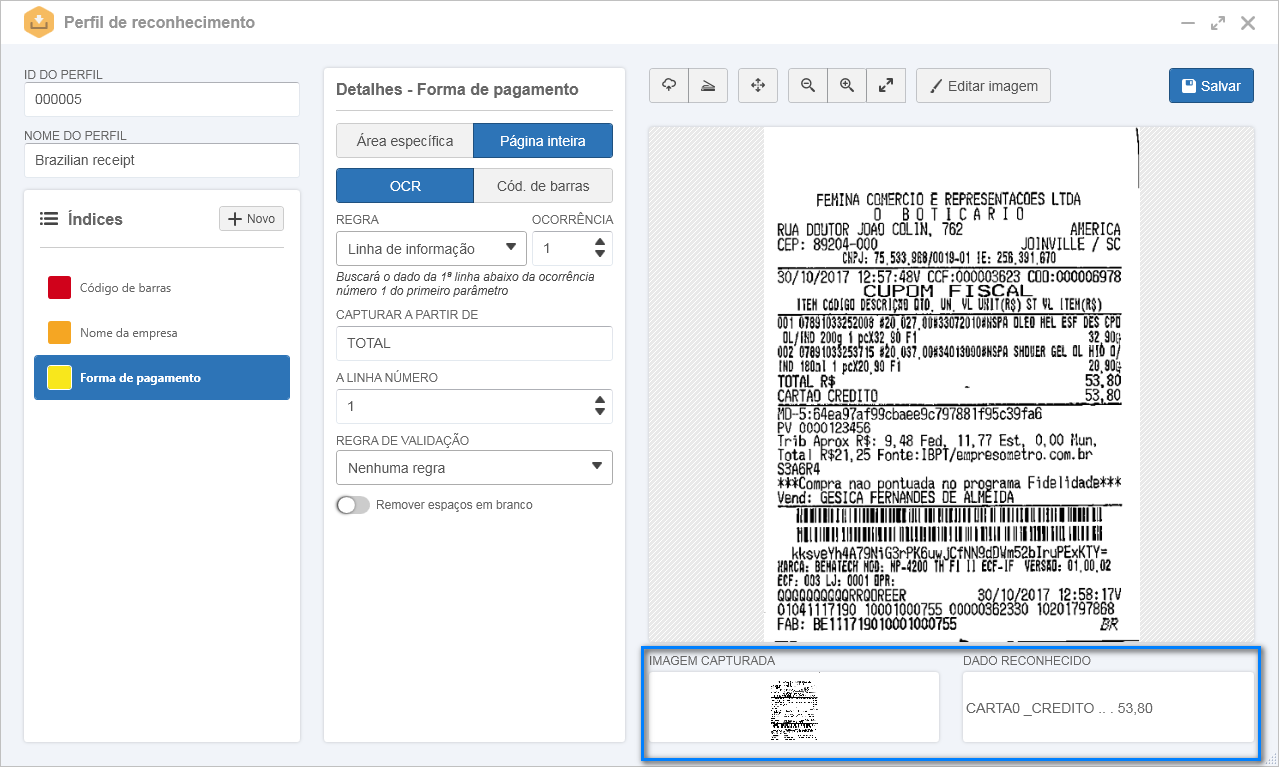
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de um cupom fiscal.
2.No painel Índices, foi configurado um índice chamado "Forma de pagamento".
3.Nos detalhes do índice, foi definido que o reconhecimento seria feito considerando a página inteira.
4.Em seguida, foi selecionada a opção OCR e a regra Linha de informação e preenchidos os seguintes campos:
Com isso, no campo Imagem capturada, é possível visualizar que foi considerada toda a página do cupom fiscal. No campo Dado reconhecido, é apresentada a forma de pagamento e o total pago, conforme especificado no cupom fiscal:
OffsetAo selecionar esta regra, o sistema realiza o reconhecimento dentro de uma área sensível da área específica ou da página inteira, de acordo com as delimitações e ocorrências configuradas. Veja a seguir um exemplo de sua aplicação:
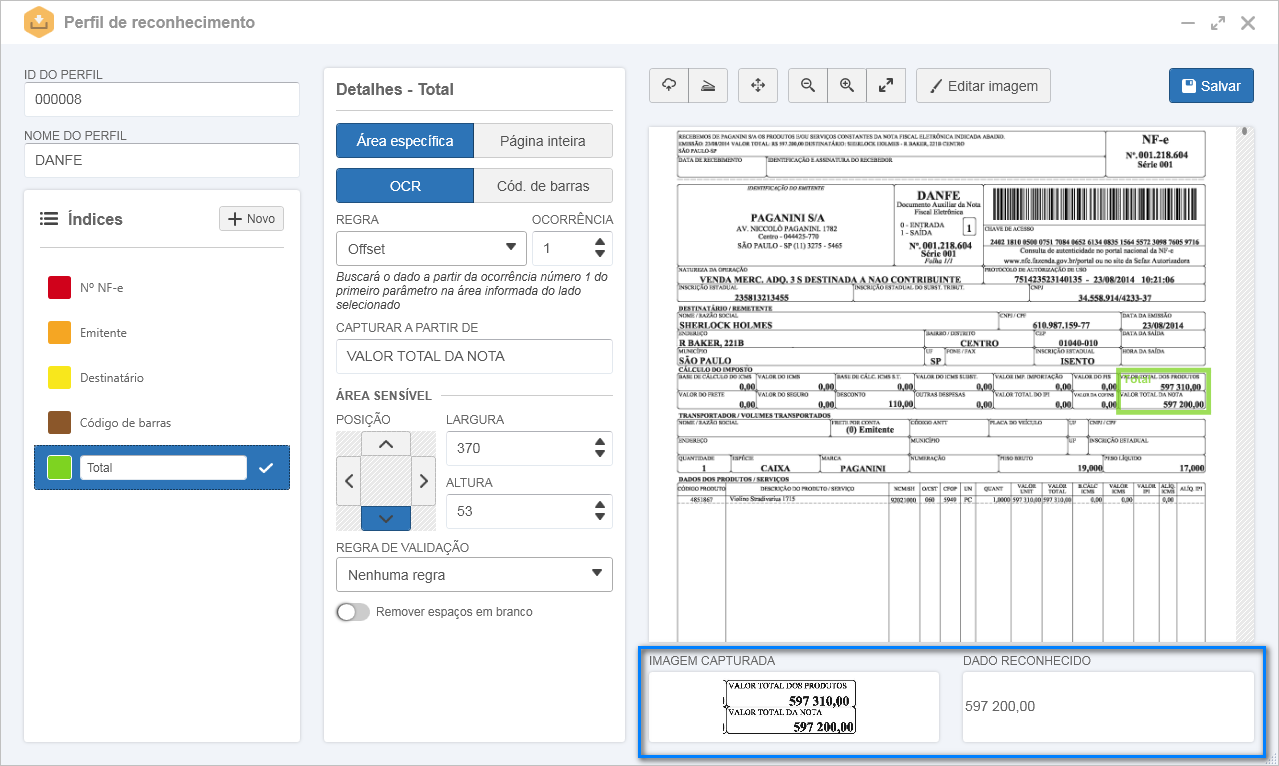
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de uma DANFE.
2.No painel Índices, foi configurado um índice chamado "Total"
3.Nos detalhes do índice, foi definido que o reconhecimento seria feito considerando uma área específica.
4.Em seguida, foi selecionada a opção OCR e a regra Offset e preenchidos os seguintes campos:
Com isso, no campo Imagem capturada, é possível visualizar que foi considerada somente a área específica da nota fiscal. No campo Dado reconhecido, é apresentado o valor total da nota:
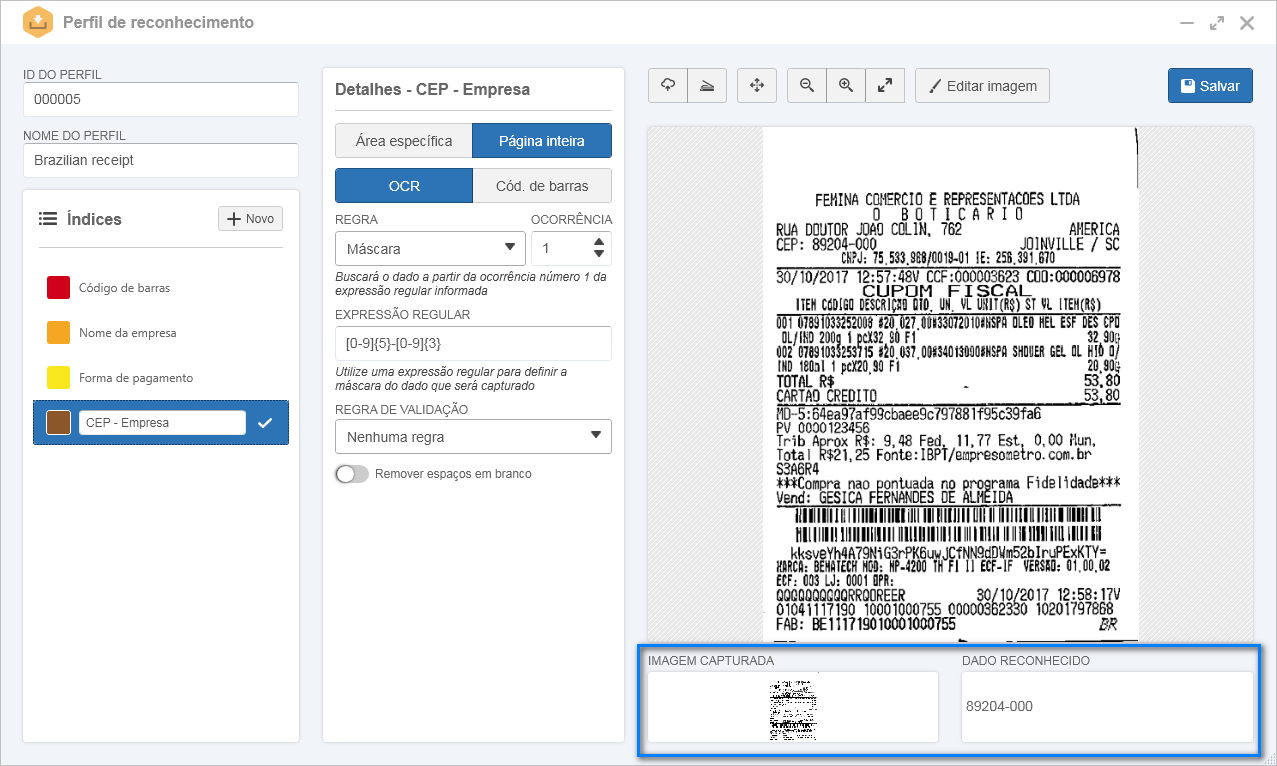
MáscaraAo selecionar esta regra, o sistema realiza o reconhecimento na área específica ou na página inteira e extrairá o valor capturado, de acordo com a expressão regular configurada. Veja a seguir um exemplo de sua aplicação:
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de um cupom fiscal.
2.No painel Índices, foi configurado um índice chamado "CEP".
3.Nos detalhes do índice, foi definido que o reconhecimento seria feito considerando a página inteira.
4.Em seguida, foi selecionada a opção OCR e a regra Máscara e preenchidos os seguintes campos:
Com isso, no campo Imagem capturada, é possível visualizar que foi considerada toda a página do cupom fiscal. No campo Dado reconhecido, é apresentado o CEP da empresa emissora do cupom fiscal:
Montagem da expressão regularUma expressão regular é uma notação para descrever um padrão de caracteres. Serve para validar entradas de dados ou fazer busca e extração de informações em textos. Por exemplo, para verificar se um dado fornecido é um número de 0,00 a 9,99 pode-se usar a expressão regular ^\d,\d\d$, pois o símbolo \d é um curinga que casa com um dígito. Os caracteres especiais ^ e $ indicam, respectivamente, como será o início e fim da linha; sem eles, os números 10,00 ou 100,123 seriam válidos, pois contém dígitos que casam com a expressão regular. Um metacaractere é um caractere ou uma sequência de caracteres com significado especial em expressões regulares. Os metacaracteres podem ser categorizados conforme seu uso.
Especificadores Especificam o conjunto de caracteres a casar em uma posição.
QuantificadoresDefinem o número permitido de repetições da expressão regular imediatamente anterior.
ÂncorasEstabelecem posições de referência para o casamento do restante da expressão regular. Note que estes metacaracteres não casam com caracteres no texto, mas sim com posições antes, depois ou entre os caracteres.
AgrupamentoDefinem ou grupos ou alternativas.
Exemplos: Veja alguns exemplos com breves explicações para ter uma ideia geral:
Valor fixoAo selecionar esta regra, o sistema permite que o usuário defina um determinado valor para ser utilizado na classificação das informações geradas a partir do perfil de reconhecimento em questão. Veja a seguir um exemplo de sua aplicação:
1.No perfil de reconhecimento, após definir um identificador e nome, foi importada a imagem de uma conta de luz.
2.No painel Índices, foi configurado um índice com o nome "Companhia".
3.No campo Regra, dos detalhes do índice, foi selecionada a opção Valor fixo. Em seguida, no campo Retorno, foi informado o nome da "Companhia de luz".
Com isso, por exemplo, é possível parametrizar na configuração da captura que todos os documentos gerados a partir do perfil de reconhecimento (com o valor fixo configurado) serão automaticamente cadastrados na categoria "Contas de luz". |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||